作者:Gaëtan Hadjeres, Marc Ferras, Khaled Koutini 等 (索尼AI)
在AI音频生成研究领域,高质量的开放模型是推动技术发展、建立性能基准的关键工具。目前,主流的音频生成模型大多关注通用音频或音乐,专门针对音效生成并开源的模型尚不多见,尤其是在追求专业级音效品质的应用场景中。
今天,小编带大家深入解读索尼AI最新发布的开源音效基础模型—— Woosh。这个模型家族专门为高质量、瞬时音效生成而优化,从底层架构到训练数据都做了针对性设计,旨在为研究社区提供一个强大的、可复现的音效生成新基准。它不仅开源了模型权重和代码,还包含了经过蒸馏的轻量版本,让开发者和研究者能在资源受限的环境下快速实验和部署。
简单来说,Woosh包含四个核心模块:
- Woosh-AE: 高质量的音频编码器/解码器,负责将音频压缩到潜在空间,并在生成后重建。
- Woosh-CLAP: 文本-音频对齐模型,确保生成的音效能准确匹配文本描述。
- Woosh-Flow/DFlow: 基于文本的音效生成扩散模型及其蒸馏版(快速推理)。
- Woosh-VFlow/DVFlow: 基于视频的音效生成扩散模型及其蒸馏版(快速推理)。
论文的主要贡献在于,它首次系统地开源了一个面向专业音效生成的完整技术栈,并在公开和私有数据集上,与StableAudio-Open、TangoFlux等知名开源模型进行了全面对比,展示了其在音效生成任务上的竞争力。
那么,Woosh具体是如何工作的?它的表现究竟如何?对于音效设计师和AI开发者来说意味着什么?我们一起来拆解。
一、架构核心:四步走,构建音效生成管线
Woosh的整体生成流程逻辑清晰,遵循了“编码-理解-生成-解码”的经典范式。下图清晰地展示了文本到音频(T2A)和视频到音频(V2A)的推理过程。
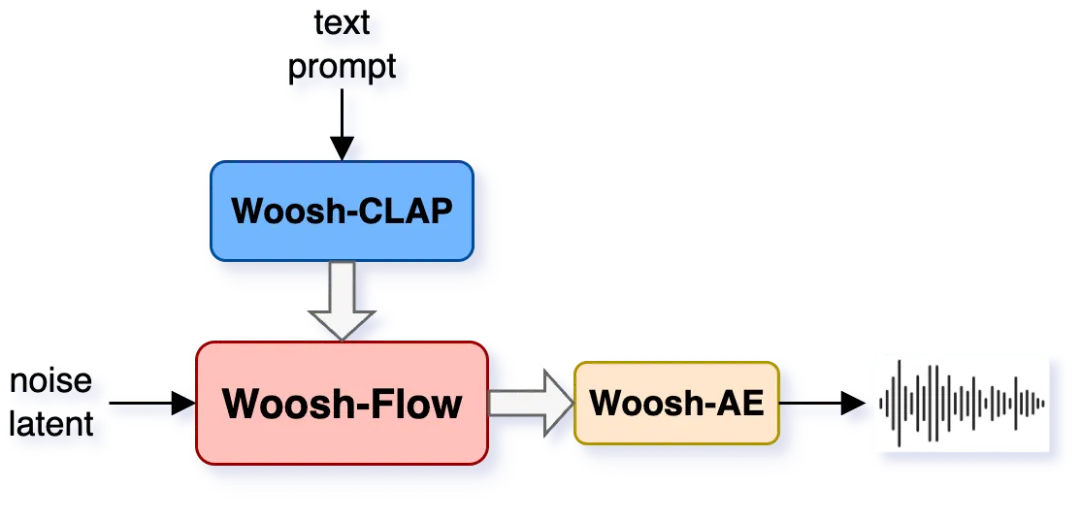 Woosh-Flow(左)和Woosh-VFlow(右)模型在推理时的布局,分别对应文本到音频和视频到音频生成
Woosh-Flow(左)和Woosh-VFlow(右)模型在推理时的布局,分别对应文本到音频和视频到音频生成整个流程可以分解为四个关键技术环节,对应着Woosh的四个核心模型。
1. 基石:高质量的音频编解码器 (Woosh-AE)
生成模型通常在潜在空间(latent space)中操作,以降低计算复杂度。因此,一个高质量的音频编解码器至关重要,它决定了原始音频能被多好地压缩和还原。
Woosh-AE选择了VOCOS架构。与Encodec、DAC等流行编解码器不同,VOCOS基于生成对抗网络(GAN),在短时傅里叶变换(STFT)的复数系数域上操作。其最大优点是避免了反卷积上采样带来的混叠伪影,通过逆STFT(iSTFT)一步到位地重建音频,能更好地保留高频细节和瞬态特性——这对于“噼啪”、“撞击”等音效至关重要。
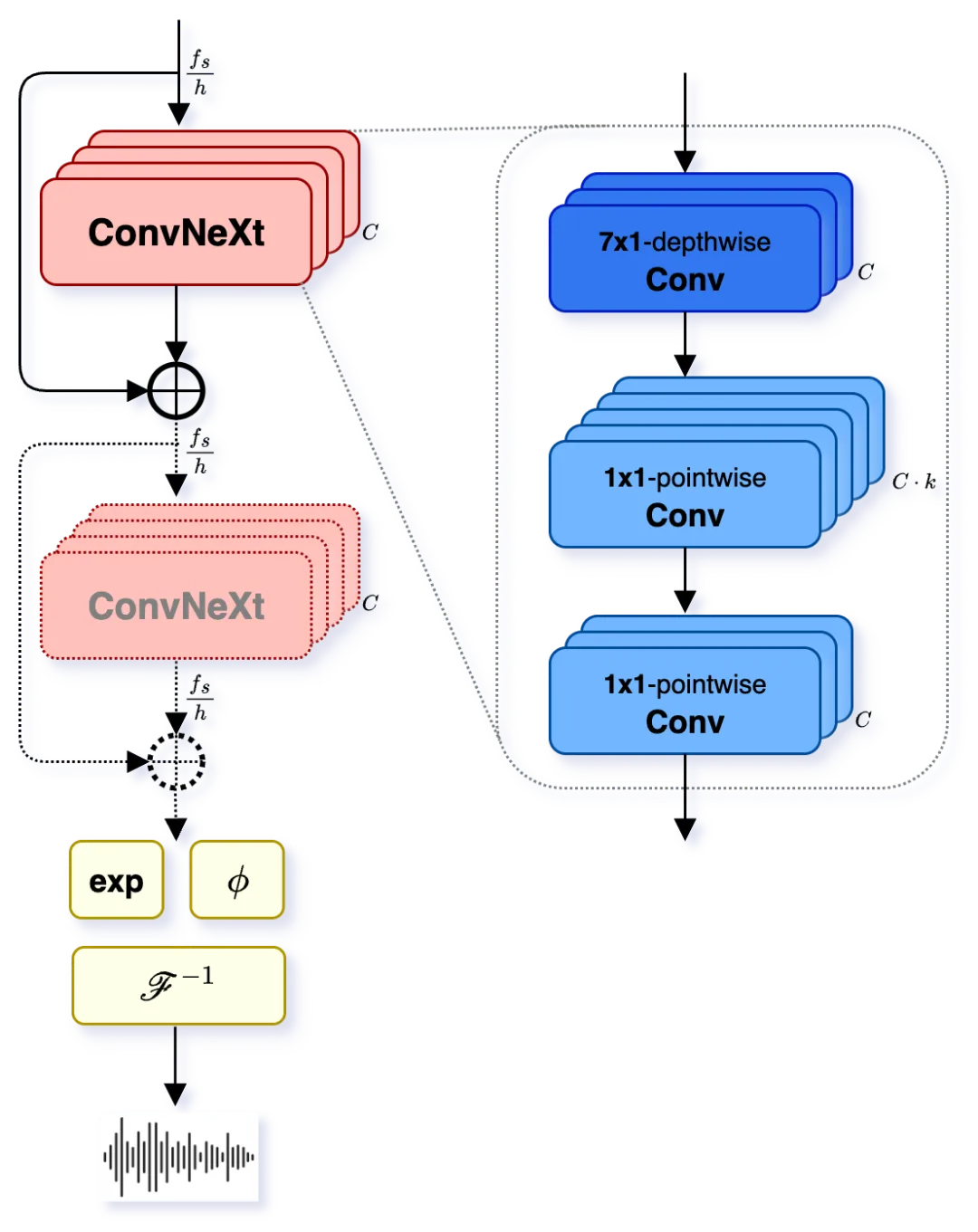 VOCOS解码器架构,作为Woosh-AE中ConvNeXt块的级联
VOCOS解码器架构,作为Woosh-AE中ConvNeXt块的级联训练数据方面,作者提供了两个版本:
- 公开版:混合了Freesound、AudioCaps、WavCaps、VCTK(语音)、内部合成音频和内部音乐数据,旨在覆盖广泛的声音类型。
- 私有版:在此基础上,加入了约100万个、总计5500小时的商业授权、工作室品质的音效库样本,这是其追求专业音质的关键。
效果如何? 在AudioCaps公开测试集上,Woosh-AE-公开版在梅尔谱距离(MelDist)指标上比StableAudio-Open的VAE降低了85%,尺度无关信噪比(SI-SDR)达到了出色的20.79 dB。即使在未使用商业音效数据训练的情况下,它在内部专业音效测试集上也表现优异,证明了其架构的通用性和鲁棒性。
2. 理解:文本与音频的对齐 (Woosh-CLAP)
要让模型“听懂”文字描述并生成对应音效,需要一个强大的文本-音频对齐模型。Woosh-CLAP采用了经典的对比语言-音频预训练方法。
- 文本编码器:强大的RoBERTa-Large模型。
- 音频编码器:采用PaSST,这是一个基于视觉Transformer的音频分类模型,能有效处理长音频。
- 训练目标:将配对的文本和音频样本的嵌入向量在共享空间中“拉近”,同时将不配对的样本“推远”。
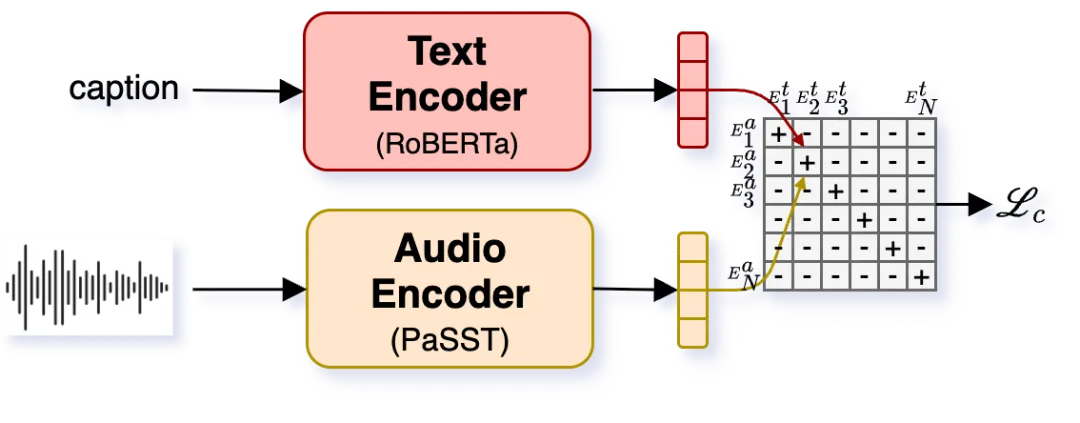 Woosh-CLAP训练框图,仅使用正样本对。生成时仅使用文本编码器进行条件控制
Woosh-CLAP训练框图,仅使用正样本对。生成时仅使用文本编码器进行条件控制一个关键发现是数据领域差异的巨大影响。在AudioCaps(公开数据)上,通用的LAION-CLAP模型检索效果更好。然而,在内部专业音效数据集上,仅用商业音效库数据训练的Woosh-CLAP-私有版实现了碾压式优势,其文本到音频检索召回率@10比LAION-CLAP高出248%!这深刻说明,面向专业领域的应用,必须使用领域内的高质量数据,公开互联网数据的描述风格和音频质量与专业需求存在显著差距。
3. 生成:文本到音效的魔法 (Woosh-Flow)
这是整个系统的核心生成引擎,一个在Woosh-AE潜在空间中操作的条件潜在扩散模型。
架构创新:Woosh-Flow基于FLUX-Kontext,采用了多模态扩散Transformer。其核心是由两种模块交替堆叠而成:
- MultiStream块:文本、噪声等不同模态的序列独立进行自注意力计算。
- SingleStream块:将所有模态的序列在时间维度拼接后,进行联合自注意力计算。这允许模型隐式地学习跨模态的关联,实现更精准的条件控制。
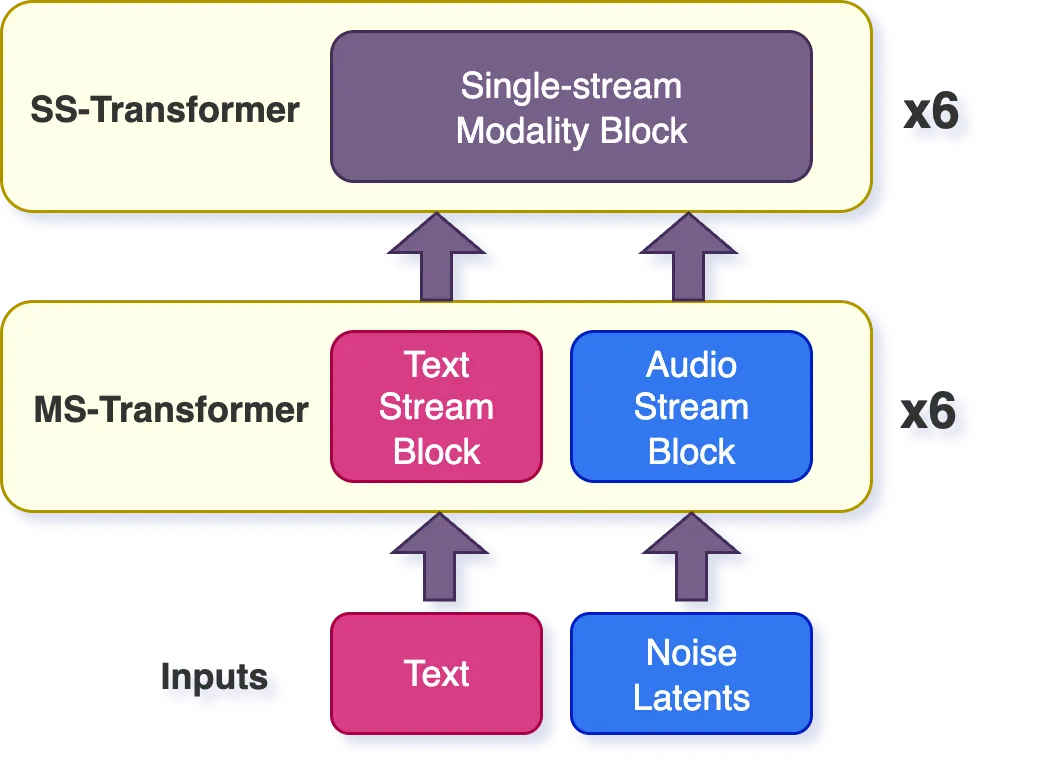 Woosh-Flow扩散模型中的多模态Transformer堆栈,由MultiStream和SingleStream块组成
Woosh-Flow扩散模型中的多模态Transformer堆栈,由MultiStream和SingleStream块组成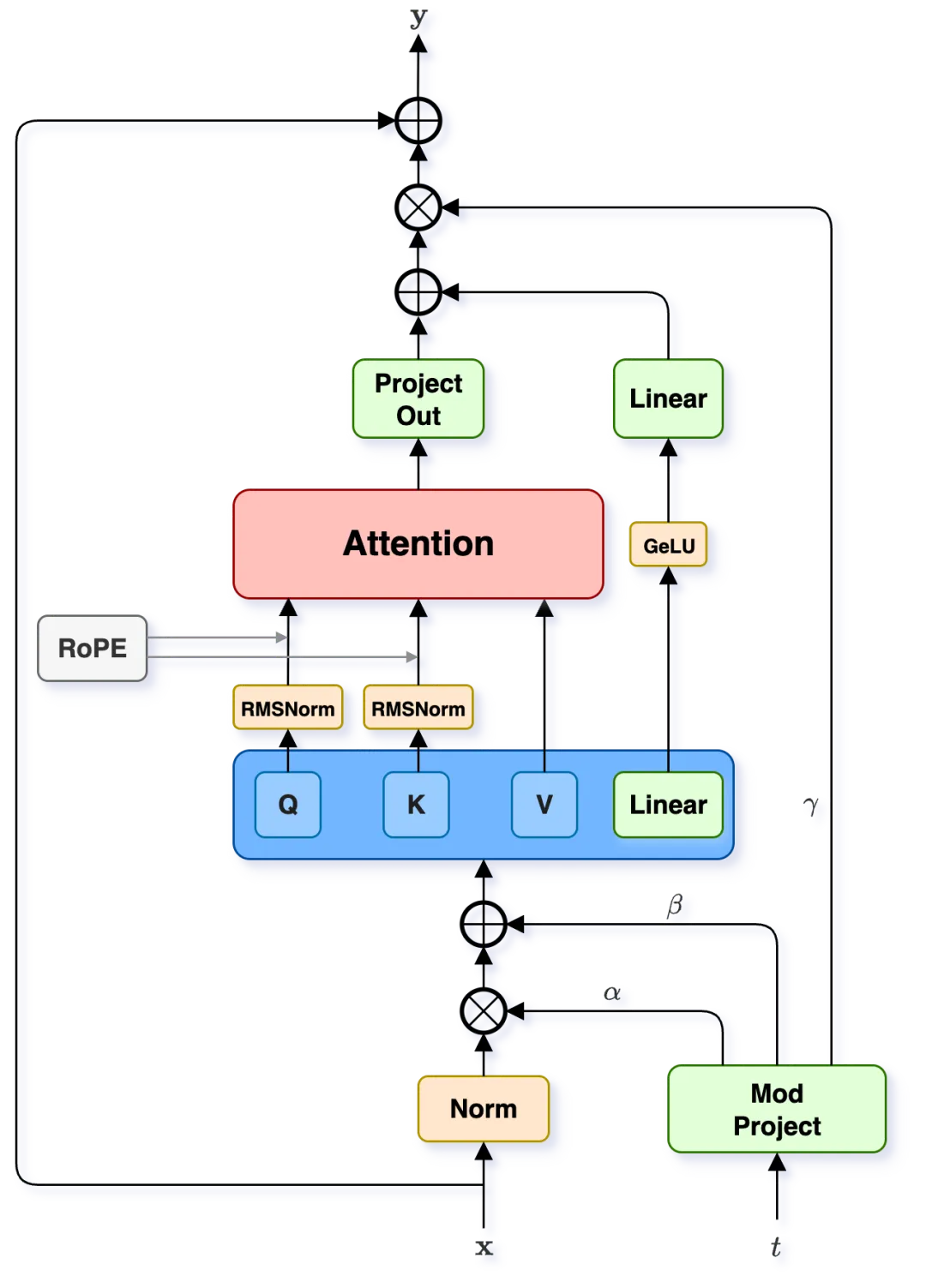 MultiStream(左)和SingleStream(右)Transformer块的详细图
MultiStream(左)和SingleStream(右)Transformer块的详细图训练与“瘦身”:
- 初代训练:使用流匹配目标进行训练,这是一种更高效的扩散模型训练方法,能学习从噪声到数据的“速度场”。
- 知识蒸馏:为了让推理速度“飞起来”,作者使用了MeanFlow方法对模型进行蒸馏,得到了Woosh-DFlow。这个过程非常巧妙,它不仅将推理所需的函数评估次数从约140次锐减到仅4次,还将分类器自由引导所需的额外计算也融入了模型,实现了“一步到位”的快速高质量生成。
生成效果对比:在AudioCaps测试集上,Woosh-Flow-公开版在Frechet音频距离(FD,衡量生成质量)和CLAP分数(衡量文本相关性)上均优于TangoFlux和StableAudio-Open。而其蒸馏版Woosh-DFlow在仅用4步推理的情况下,性能虽有下降,但仍保持了相当的竞争力。
4. 扩展:从画面到声音 (Woosh-VFlow)
更有趣的是,Woosh框架可以轻松扩展到视频生成音效的任务。作者在Woosh-Flow的基础上,引入了第三个模态——视频。
- 视频编码:使用SynchFormer模型提取视频帧的特征。
- 架构修改:对原有的MultiStream块进行改造,为视频模态新增独立的投影层和前馈网络,使其能够与文本、音频潜在表示进行联合注意力计算。
- 训练数据挑战:视频-音频数据对往往存在描述不准、音画不同步等问题。为此,作者使用Qwen3-Omni音频-语言模型为VGGSound和OGameData数据集生成了更准确的合成字幕,用于辅助训练。
同样地,视频生成模型也经过了蒸馏,得到了快速推理版本Woosh-DVFlow。
二、实验结果:专业领域,优势尽显
论文在公开数据集(AudioCaps)和内部专业音效数据集(InternalSFX)上对Woosh的各个模块进行了全面评估。
音频编解码器:重建质量领先
下表清晰展示了Woosh-AE在重建质量上的巨大优势。无论是公开版还是私有版,其各项失真指标都远低于其他对比模型。
| 模型 | 采样率 | 参数量 | AudioCaps-Test (梅尔距离↓) | InternalSFX-Test (梅尔距离↓) |
|---|
| StableAudio-Open VAE | 44.1 kHz | 156M | 0.217 | 0.121 |
| Woosh-AE-公开版 | 48 kHz | 221M | 0.032 | 0.021 |
| Woosh-AE-私有版 | 48 kHz | 221M | 0.074 | 0.024 |
文本-音频对齐:领域数据决定胜负
Woosh-CLAP在不同数据域的表现差异,是论文最有趣的发现之一,强调了数据与任务匹配的重要性。
| 模型 | 训练数据 | AudioCaps-Test (T2A R@10) | InternalSFX-Test (T2A R@10) |
|---|
| LAION-CLAP | 大规模公开数据 | 0.618 | 0.188 |
| Woosh-CLAP-公开版 | 公开音频数据集 | 0.546 | 0.198 |
| Woosh-CLAP-私有版 | 商业音效库 | 0.167 | 0.655 |
在专业音效数据上,私有版模型的检索准确率是通用模型的3倍以上。
音效生成:质量与效率的平衡
在音效生成任务上,Woosh-Flow展示了优异的综合性能,而其蒸馏版则在速度上实现了突破。
| 模型 | 参数量 | 推理步数 (NFEs) | AudioCaps-Test (FD↓) | InternalSFX-Test (FD↓) |
|---|
| StableAudio-Open | 1057M | ~200 | 150.1 | 341.0 |
| TangoFlux | 515M | ~200 | 131.9 | 378.1 |
| Woosh-Flow-公开版 | 337M | ~140 | 109.1 | 282.7 |
| Woosh-DFlow-公开版 | 337M | 4 | 132.1 | 322.5 |
| Woosh-Flow-私有版 | 337M | ~140 | 213.8 | 246.9 |
关键结论:
- 公开数据上:Woosh-Flow-公开版以更少的参数量,取得了最好的生成质量(FD最低)。
- 专业数据上:Woosh-Flow-私有版优势明显,其FD分数远低于其他所有使用公开数据训练的模型。这再次印证了“专业的事需要专业的数据”。
- 效率:Woosh-DFlow仅用4步推理,性能虽略有折损,但在速度上实现了数十倍的提升,为实时应用打开了大门。
视频生成音效:同步与质量兼得
在视频生成音效的评测中,Woosh-VFlow在FoleyBench和OGameData数据集上,相比参数更多的MMAudio-M基线模型,在音频质量(FD, KL)和音画相关性(IB)等指标上表现更优或相当。
例如,在OGameData数据集上,Woosh-VFlow的FD分数(11.15)远低于MMAudio-M(87.19),表明其生成的音频在分布上更接近真实音频。同时,其蒸馏版Woosh-DVFlow同样保持了快速推理的优势。
三、未来展望:Woosh开启的音效创作新可能
Woosh的发布不仅仅是一个模型,更是一个音效AI应用开发的基石。论文也展望了基于Woosh可以展开的一系列激动人心的方向,这些对于游戏、影视、广播等领域的音效设计师来说极具吸引力:
- 精细化控制:基于响度、频谱等声学属性进行时间轴级别的精确控制。
- 声音变体生成:给定一个脚步声样本,生成一系列相似但略有不同的脚步声,丰富游戏音频。
- 音频修复与补全:类似图像inpainting,对一段音频的缺失部分进行智能补全。
- 个性化定制:仅用少量样本(如一种特定的武器音效),让模型学习并生成具有一致风格的新音效。
- 声音渐变:根据文本描述,将一种声音平滑地“ morph ”成另一种声音。
结论:为专业音效生成设立开源新标杆
总结来看,索尼AI的Woosh项目是一次高质量的“开源投喂”。它系统性地构建并开源了首个专门针对高质量音效生成的基础模型家族,覆盖了从编码、对齐到生成(文本/视频条件)的完整技术链。
其核心价值在于:
- 领域专用性:从架构到数据,紧紧围绕“专业音效”这一目标进行优化。
- 性能验证:在公开和私有数据集的评测中,证明了其相对于现有开源方案的竞争力,尤其在专业数据领域优势显著。
- 实用性:提供了蒸馏模型,兼顾了研究探索与快速部署的需求。
- 生态启发性:为后续的声音编辑、控制、个性化等高级应用提供了强大的底层支持。
这项工作的一个深远启示是:在追求专业级AI应用的路上,通用互联网数据与垂直领域高质量数据之间存在巨大鸿沟。Woosh的成功,很大程度上归功于其对专业音效库数据的运用。对于AI音频研究者、音效工具开发者以及创意产业的从业者而言,Woosh无疑是一个值得深入探索和构建的绝佳起点。
项目地址:https://github.com/SonyResearch/Woosh在线试听:https://sonyresearch.github.io/Woosh/
关注「AI论文热榜」,紧跟最前沿、最硬核的AI技术进展!
如有论文辅导、项目开发等需求,请联系小编,微信号: GCgcong
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
